


Today we continue the series of articles that aims at presenting the basics of the ZFS. In today’s article we’re further discussing this topic, focusing on the notions of data integrity as well as on the concept of RAID applied in ZFS. Read on and learn!
ZFS-enabled Data Integrity
The ZFS-based systems are designed to protect the data against silent data corruption, among others, caused by parity errors, accidental overwrites, disk firmware bugs, phantom writes, and driver errors.
The copy-on-write mechanism that was described in the previous part of the series was one of the methods ZFS uses to keep consistent data on the disk. You can read this article here: ZFS Essentials: Copy-on-Write & Snapshots. This particular file system ensures to always write the checksum on the disk. Subsequently, when the data is read again, this information is calculated once more. If a mismatch in the checksum is detected, then an attempt will be made to correct the error, provided that the data redundancy is available. This operation is done automatically, without the user’s knowledge.
The data integrity is carried out by using either one of the following on the whole file system tree:
- Fletcher-based checksum
- SHA-256 hash
When accessing the block of data or metadata, a checksum of it is calculated and compared with the suggested stored checksum value. If the checksum of the read data matches the checksum of the written data, the information is passed further. In case when the checksums do not match, ZFS will attempt to repair the data provided there is enough redundancy retained for this data, for example, there is a mirror copy of it. If other copies of corrupted data exist, or it is possible to rebuild it using checksums and parity information, the system will attempt to calculate the checksums once more to reproduce the value that was initially expected. ZFS can afterward use such data to update the damaged resources with functioning copies.
ZFS RAID
In general, the whole pool can consist of one or several vdevs that are combined in the pool as RAID0 (STRIPE). Each vdev can be built from a single volume, mirror or RAIDZ1, RAIDZ2, or RAIDZ3. The redundancy of the vdevs is important to the pool since losing one vdev leads to the whole zpool being lost. The following image illustrates the RAID levels used in ZFS:
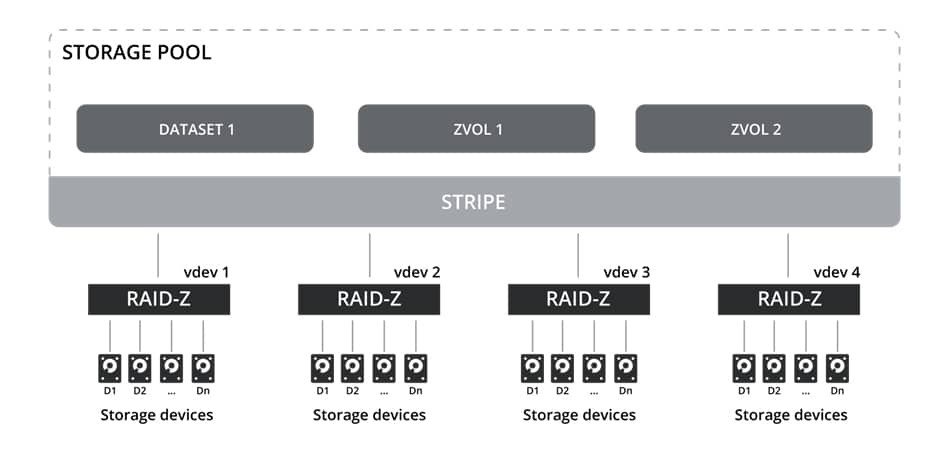
The RAID types are described below:
- Single – it is a vdev consisting of a single disk, and provides no parity nor a mirror in case of a physical disk failure. This setup is not recommended since losing one drive might result in losing all available data. This configuration of the pool is similar to RAID0.
- Mirror – allows using multiple mirrors to provide data redundancy. This configuration is similar to RAID1. For example, you can lose one disk out of two available disks in a vdev. In the case of multiple vdevs, the whole pool configuration is similar to RAID10.
- RAIDZ1 – is similar to RAID5 but without the write hole issue, the original RAID5 suffered from. A single disk in a vdev can be lost to maintain data integrity. In the case of multiple vdevs, the whole pool configuration is similar to RAID50.
- RAIDZ2 – resembles RAID6 which allows losing two disks in a vdev and maintaining data integrity. In the case of multiple vdevs, the whole pool configuration is similar to RAID60.
- RAIDZ3 – has to have a minimum of five storage drives in vdev where three drives are used for parity. Losing three disks in a vdev is permitted before data in the Zpool is lost.
Closing Notes
The data integrity mechanisms, as well as RAID levels integrated in the system, provide data security capabilities that traditional file systems do not possess. Not only you are able to retrieve your data, provided that you have the required data redundancy secured but also your system will be well protected against various threats and issues that might result in losing the data.
In case you’ve missed the two previous parts of this article series, you can read them here:


Leave a Comment