


Data fragmentation is one of the biggest challenges for any enterprise company whose work involves processing and sharing information. It creates data silos that obstruct the efficiency of various departments requiring accurate and dependable data for their operations. While it’s essential for each team to have access to current and reliable shared data, they also utilize unique data that can become obscured within complex infrastructure. This paradox underscores the challenge of managing data in an enterprise business. So, what is the best solution to avoid data storage fragmentation? Choosing the right way to centralize data storage seems to be the solution!
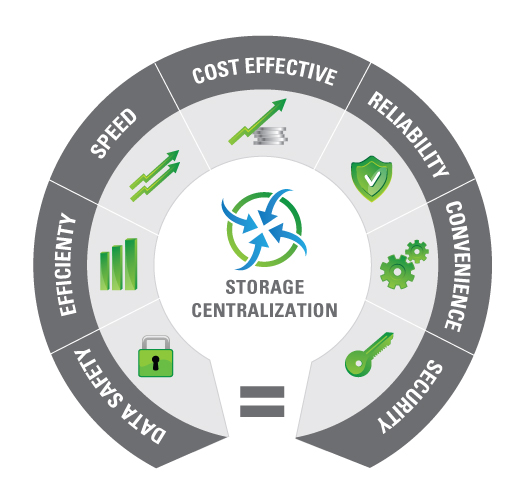
Data Storage Centralization Benefits
Data storage fragmentation causes an enormous maintenance burden that requires lots of resources and effort to manage and maintain the infrastructure on multiple machines or systems. There are several techniques to decrease or even eliminate it. Using Software-defined Storage, especially Hyper-converged Infrastructure, which treats all storage devices on a network as a single data pool, makes it relatively easy to scale any environment once needed. It simplifies the management by eliminating unexpected lack of space and preventing squandering. But centralized data storage architecture is the most effective of all, combining the above features while giving much more. So, what are the other benefits of using it? Let’s find out!
Cost-effectiveness, Reliability, and Performance…
First of all, it is much more cost-effective. I have already mentioned more efficient use of resources by distributing storage and computing power based on demand, preventing idle resources. Management costs are also diminished by reducing the entire infrastructure to a globally managed data storage system, eliminating the need to maintain multiple ones. On the other hand, centralization requires less hardware and software, which makes it much cheaper to maintain. Time and labor costs are much lower because fewer upgrades and troubleshooting are needed. Sharing storage is much facilitated, ensuring more efficient distribution and utilization of capacity. Finally, in a centralized architecture, transferring data between employees or customers is faster and simpler, reducing the load on the network and lowering the bandwidth needed to meet the corresponding business needs.
Centralized storage systems are also more efficient in terms of power supply and peripheral equipment required to fulfill enterprise business demands. It is better to supply a central server than to power several individual machines. The same thing applies to any peripheral equipment – it’s more efficient and less time-consuming if fewer separate units are being used.
… In Favour of Productivity
Let’s not forget about the productivity of employees who rely on the data managed by the company. They have better access to data if it’s concentrated in a centralized data storage infrastructure. Management is easier, accessibility is faster, and integration with other systems is seamless. The company has better control over the data distributed across various departments, so the whole workflow is much more effective. It refers to giving relevant permissions to access certain data and provides the basis for better collaboration between these departments, sometimes spread across the world, which saves time and gives more profits. If the company relies on multiple departments with hundreds (or thousands) of employees in a centralized data storage infrastructure, it’s easier to prevent data duplication. Deduplication eliminates unnecessary data, keeping only of those that are redundant for a reason (backups). This technique improves storage utilization and reduces storage costs.
Data Storage Centralization Benefits
Data Storage Centralization Challenges and Possible Solutions
Of course, data centralization faces some challenges, but there are methods to avoid them or prevent them from impacting the business on a big scale.
Data Quality
Nowadays, it is very common for organizations to struggle with data distributed across multiple platforms. Data fragmentation presents a significant challenge – maintaining consistency and accuracy. When data is scattered this way, it becomes vulnerable to discrepancies, leading to potential inaccuracies and inconsistencies. This lack of unity results in poor decision-making, affecting the overall productivity and efficiency of the whole organization.
The concept of centralized data storage systems has emerged as a compelling solution to address this challenge. By centralizing data, organizations can significantly enhance the quality and reliability of their information. This is achieved by creating a ‘single source of truth’ – a unified, consistent, and accurate source of information that is readily accessible to all departments within the organization.
The centralized system acts as a repository that consolidates data from various sources into one location. This consolidation eliminates the risk of data duplication and discrepancies, ensuring that everyone in the organization is working with the same accurate information and figures. Moreover, a centralized data storage system simplifies its management by providing an efficient process for data entry, retrieval, and maintenance. This in turn, leads to increased productivity and efficiency. So, it can be said that a centralized data storage system not only improves the quality and accuracy of data but also contributes to conscious decision-making and strategic planning.
Data Protection in Centralized Systems
While offering multiple benefits described above, the centralization of data can unintentionally make the coalesced data a more appealing target for cyber threats and the storage system hardware much more vulnerable to natural disasters. This is due to the concentration of valuable information in a single location.
To counter these threats, organizations can adopt a multidimensional strategy. This includes implementing robust security measures such as data encryption, secure user authentication, regular security audits, applying various forms of failover, as well as applying a ZFS-based storage system offering snapshots and retention plans, On- and Off-site Data Protection methods, and the High-Availability Cluster. Collectively, these measures work to safeguard the centralized data from potential cyber-attacks, human errors, and natural threats.
Snapshots and retention plans provide a point-in-time copy of the data, allowing it to quickly revert to a previous system state. In the context of cyber threats, after the attack, snapshots can be used to restore the data to its state before the attack. Retention plans, on the other hand, dictate when snapshots are being made and how long kept before they are automatically deleted. In the case of ransomware attacks, where data is encrypted and held hostage by hackers, having a retention plan enabled allows organizations to restore data from a snapshot taken before the attack. This can significantly reduce downtime and data loss.
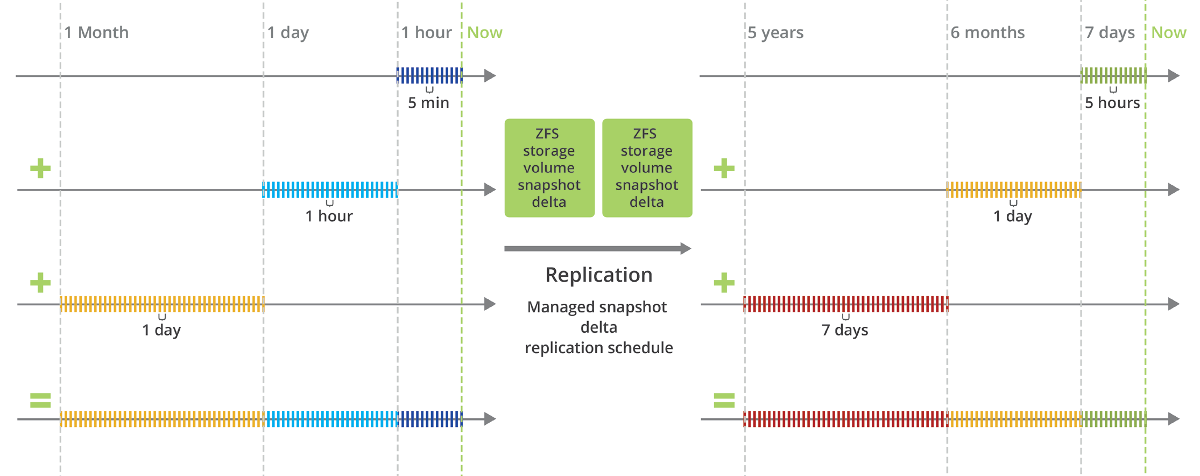
Snapshots and retention plan scheme
Except that there are three other types of data protection and providing full business continuity. A failover system ensures that in the event of a server failure, the system automatically switches to a standby server, network, or system. This ensures continuous operation and minimizes the impact of system failures on business operations. On- and Off-site Data Protection strategy is another critical component of a comprehensive data protection strategy. By storing backup data in a geographically separate location, organizations can ensure data recovery in the event of a site-specific disaster such as a fire or flood. Open-E High-Availability Cluster can further enhance data security and provide full business continuity. By linking servers together, it provides the whole node redundancy. Hence, if one server fails, the workload is automatically transferred to another server in the cluster, ensuring uninterrupted service.
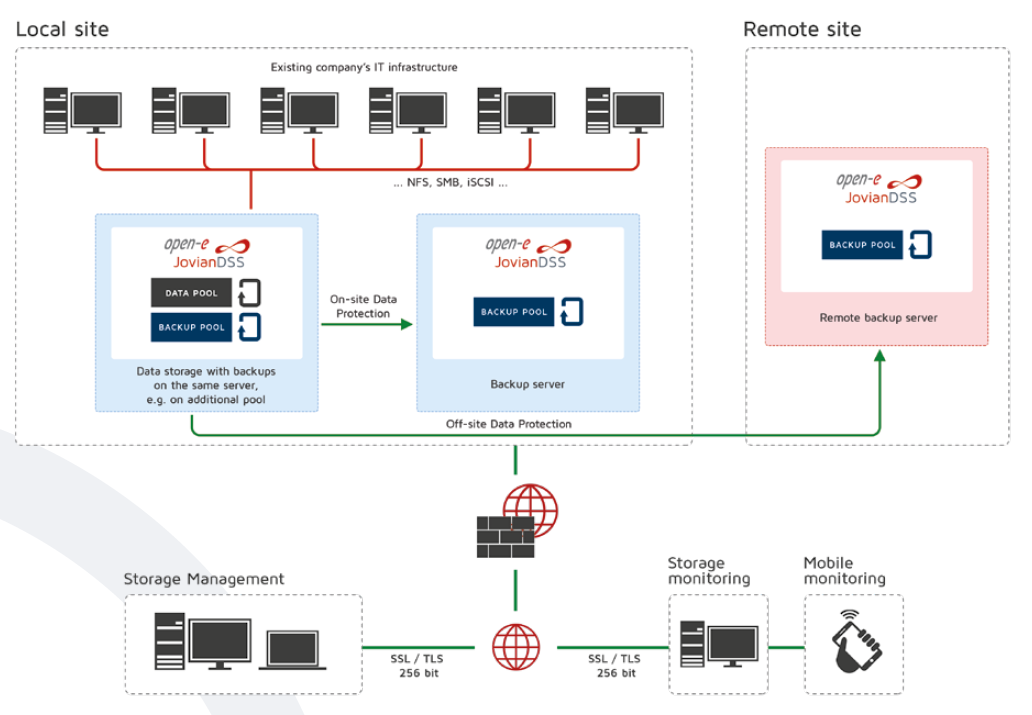
Open-E On- & Off-Site Data Protection
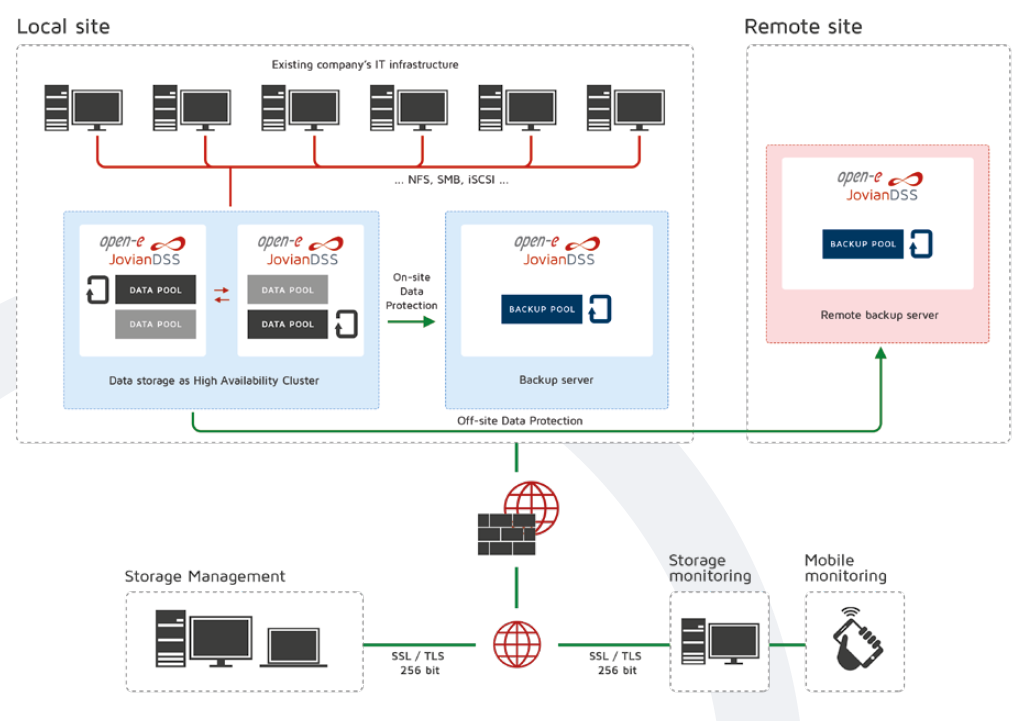
Open-E High-Availability Cluster
Escalating Data Volume
With the increasing amount of data across all functions, managing and safeguarding it can be a daunting task. The challenge is to develop an efficient and secure system that can handle the growing data volumes while ensuring data privacy, security, and integrity. The system should be scalable, cost-effective, and easy to maintain.
Using advanced technologies, such as artificial intelligence (AI) and machine learning (ML), seems the most effective strategy. Implementing robust data management systems and leveraging technologies like AI and ML significantly improves the administration of large data volumes. These systems are capable of handling large-scale data, ensuring its availability, and safeguarding it against potential threats. They have the potential for automatization in data management, thus minimizing manual work and the risk of human error. AI and ML improve data security by identifying areas where data management can be done more efficiently. They can analyze large data sets, recognize complex patterns, and generate insights, allowing organizations to make data-driven decisions. They also improve data storage by ensuring the right data is available to the right people at the right time. As a result, this strategy solves current problems and prepares organizations for future data expansion as AI and ML possibilities constantly expand.
Implementation via NAS and SAN
A centralized storage infrastructure can be implemented using one of two environments – NAS and SAN. Network-attached storage and storage area network environments have several similarities, but both have different advantages and disadvantages in terms of functionality and performance when used. They provide centralized management, allowing for easier control and administration of data. Both offer data accessibility by delivering a single centralized storage location for multiple devices on a network, enabling data to be accessed as a shared resource. Both systems often use a RAID configuration for data redundancy, ensuring data protection and recovery during a drive failure. Physical devices (disks) are grouped into one space, creating logical/virtual volumes that are then made available to users In terms of scalability, SAN and NAS systems can be expanded to meet growing data needs, both are designed to deliver high throughput and low latency, making them suitable for enterprise storage options. These features make NAS or SAN integral to any organization’s data management strategy. However, they work a bit differently, so let’s look at the advantages and disadvantages to see if one can be more reliable and worth applying to company storage architecture.
Feature | NAS | SAN | Description |
|---|---|---|---|
Database Systems Coherence |  |  | Compatibility with database systems such as Oracle or Microsoft Exchange with exception of SQL or block devices |
Creating Snapshots | | | NAS is better as per excellent use of virtualization, which supports the use of snapshots |
Database Support | | | SAN is compatible with databases that necessitate the use of block devices |
Direct Data Access | | | SAN does not offer direct access to the stored data. Hence, exceptional attention must be paid to provide consistency between the original and replicated data stored by the external application |
Ease of Use | | | NAS devices are generally easier to set up and manage, making them a popular choice for businesses |
Network Protocols | SMB + NFS + FTP/FTPS/SFTP + AFP + WebDAV | FC/FCoE + iSCSI + InfiniBand | |
Immediate Disk Space Access | | | Newly attached block devices can be quickly implemented into the server, and the existing ones can be easily duplicated |
Native File System | | | Allows using a native file system of applications |
Direct Shared Data Access | | | SAN volumes are designed for data sharing in a different way than NAS and thus require an additional compatible file system |
Versatility | | | A versatile solution that can serve as a collaborative file server, web server, virtual machine, and media center |
What is your opinion? What does your company prefer to use? Is it the NAS or SAN environment? Or do you prefer a completely different approach by opting for decentralized data storage? Go ahead, we look forward to hearing from you in the comments section!


Leave a Comment